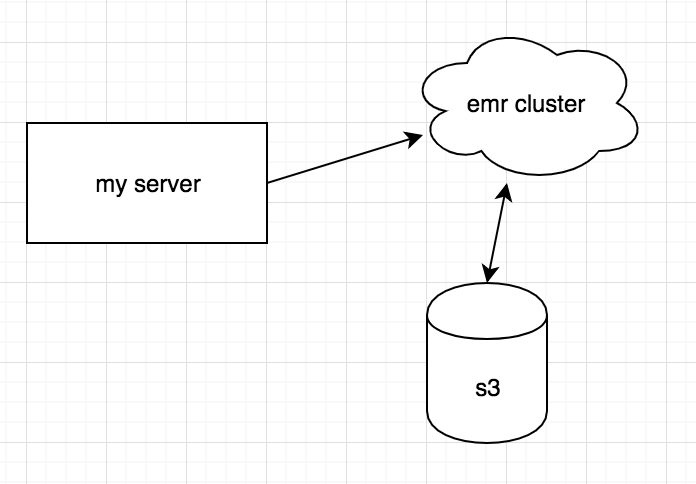
어떤 디비든간에 특정 컬럼에 대해서 검색이 잦을 경우 그 컬럼에 인덱스를 걸어놓는다. 인덱스를 걸어놓으면 해당 컬럼에 대한 작업시 속도가 상당히 빨라진다. 나도 개발자로 일하기 전에는 속도에 이슈가 생길만큼.. 큰 디비를 다뤄본적이 없는지라 회사에서 중요한 인덱스 개념을 처음 습득했다.(인덱스 안걸면 진짜 죽음이다.) 어쨋든 현재 5억건의 데이터를 가지고 있는 몽고 디비가 있는데, 어떤 컬럼이 추가되면서 그 컬럼에 인덱스를 걸어야 할 일이 생겼다. 평소라면 그냥 인덱스를 걸었겠지만 문제는 이 몽고디비가 계속 사용중인 production이라는것과, 5억건의 데이터에 인덱스를 걸려면 경험상 3~4시간이 필요했다.(서버 성능에 따라 다르긴하지만) 몽고디비를 거의 나만 쓰고 있어서 모든 컬렉션들을 컨트롤하고있다..