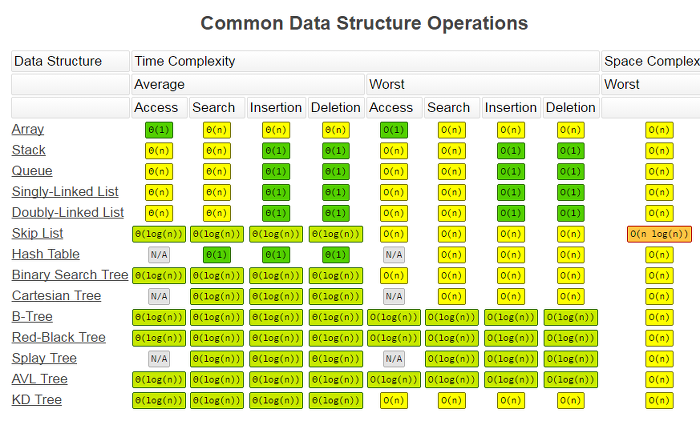
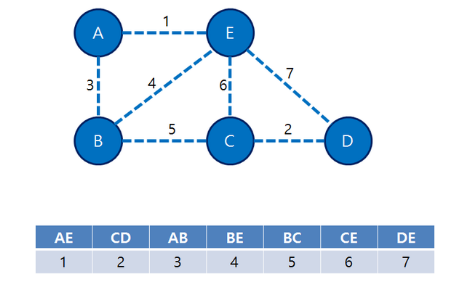
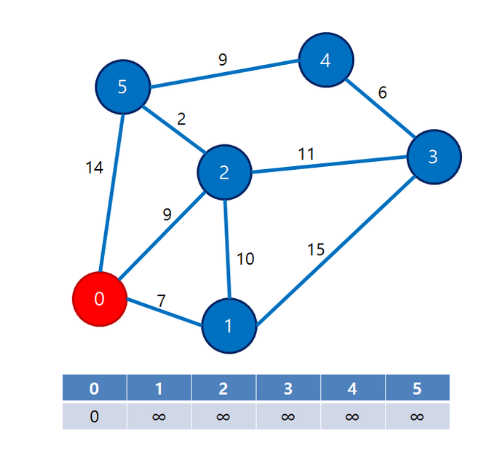
https://qkqhxla1.tistory.com/700 그림을 다시 가져옴.아주 예전에 정리했었는데 c++이고.. 좀 복잡해서 지나면 잊어버린다. 파이썬 딕셔너리로 쉽게 구현한 버전이 있어서 가져왔다. MyPrettyPrinter클래스는 디버깅용이니 무시하고 Trie클래스만 보자. 소스 출처 : https://leetcode.com/problems/add-and-search-word-data-structure-design/discuss/59700/Python-trie-solution-search-using-dfs 여기서 가져와서 보기좋게 가공했다. addWord로 단어가 추가되면 트라이를 구성하는데, 단어가 어떻게 구성되는지는 아래에 print MyPrettyPrinter().pformat(t.tri..