앱을 지우고 재설치해도 계속 뜨고 버전을 조금 낮춰봐도 에러가 뜬다. 구글링을 몇일동안 죽어라 해도 원인을 찾을수 없어서 포기했다. chart버전을 아예 2버전대로 확 낮춰보니 제대로 설치가 되긴 하는데 chart버전이 낮으니 당연히 spark버전도 낮다. 난 최소 스파크 3.0.1이상이 필요한데.. 결국 helm을 공부해서 직접 cli로 설치해보면서 왜 안되는지 디버깅해보기로 마음먹었다.(닥치니 이제서야...) helm도 사실 잘 몰라서 뭔가 공부하기 빡세지 않을까.. 하는 미지의 두려움이 있었는데, 막상 공부해보니까 쉬웠다. helm은 공식 튜토리얼을 보고 가볍게 익혔다 : helm.sh/ko/docs/intro/quickstart/
공식 튜토리얼을 읽고, 내 노트북의 ~/.kube/config 경로에 쿠버네티스 클러스터 정보를 넣은 후,(이래야 내가 helm으로 앱을 설치했을때 우리 쿠버네티스에 설치가 된다.) helm 튜토리얼에 나온대로 간단하게 spark를 설치해봤다.
helm install spark-test bitnami/spark ->로 설치해본결과 기본적인 옵션으로 spark-test가 설치됨을 확인할수 있었다. helm install시 버전 인자를 주지 않으면 가장 최신 차트 버전으로 설치가 되는데 내가 위에서 gui로는 몇번 재설치해도 안되었었던 5.4.0이 나도모르게 그냥 뿅 하고 설치가 되버렸다.(??)
여기서 추측한 문제점이.... 랜쳐에 있는 helm버전이 오래되어서 저 문법이 맞는것임에도 에러가 났던게 아닌가 생각한다. 방금 맥에서 brew로 설치한 helm으로 5.4.0버전의 chart가 문제없이 설치되었기 때문이다. 어쨌든 되니까 cli로 계속 해보기로 마음먹었다.
helm list를 입력해보면 내가 설치한 spark-test가 보이고, helm uninstall spark-test로 설치한 spark-test를 지울수 있다. 이제는 설정값을 넣어서 제대로 설치해보자.
스파크는 3.0.1버전이 필요하며, 이것에 맞는 chart버전은 5.1.2임을 알아낼수 있었다. artifacthub.io/packages/helm/bitnami/spark/5.1.2 그리고 namespace는 spark로 설정하고, 나중에 추가한건데 쿠버네티스 내부 뿐만 아니라 다른곳에서도 접근이 필요했기에 nodeport로 서비스한다. nodeport로 접근시 포트는 깔끔하게 30000으로 할거고, worker는 4대를 만들거다. nodeport로 서비스하는등 그런 인자값은 위의 artifacthub.io 링크에 잘 나와있고, helm으로 설정시에는 --set으로 설정해준다. helm 설명은 위에 링크를 걸어놓은 helm 공식문서에 설명이 잘 되어있다. 결국 아래와 같은 옵션으로 spark를 만들었다.(이것도 다른것때문에 엄청 삽질한듯)
total-executor-cores는 워커 4개를 만들고 코어가 각각 1개씩인만큼 가지고 있는 4개를 넘어가면 자원이 부족하다고 실행이 안되긴 했지만 줄여서 잘 돌아갔다. 여기까진 쉽게 됐다.. 여기까지 되고나서 아 이제 뭐 네트워크가 달라져도 nodeport로 열어놨으니까 그냥 spark-submit만 잘하면 되겠네?? 라고 생각했는데 그게 또 아니었다.
1. 같은 aws 네트워크 안에서 마스터를 호출하는건 가능했지만,(위에 잘된 경우.) 2. 같은 aws 네트워크지만 spark-submit쪽이 docker로 한번 감싸지면 안되었고, 3. 또는 내 로컬 네트워크에서 spark-submit을 하면 안되었다.(nodeport로 열려있음에도 불구하고) 나중에 적겠지만 포트를 열어줘야 해서 3번은 포기했다.
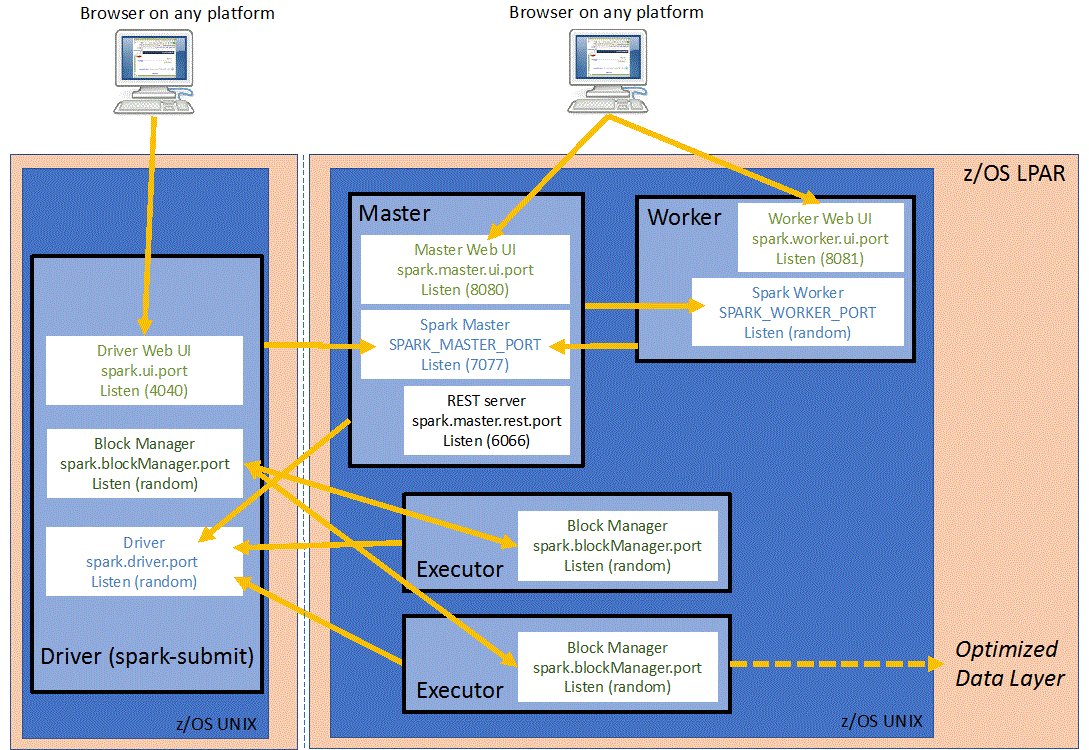
아래는 내가 시도하려는 2번의 경우를 간단하게 표현했다.. 쿠버네티스 환경 안에서 pod2안에 spark master가 있고, 또다른 pod1에서 도는 docker에서 pod2에 있는 spark master를 호출하고자 한다.(사실 더 따지자면 이것도 아니지만 간단하게 표현했다.)
도커로 한번 감쌌을뿐인데 잡이 제대로 작동이 되지 않는다.
21/04/06 09:37:31 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20210406093716-0015/8 is now RUNNING
2021. 4. 6. 오후 6:37:33 21/04/06 09:37:33 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20210406093716-0015/8 is now EXITED (Command exited with code 1)
2021. 4. 6. 오후 6:37:33 21/04/06 09:37:33 INFO StandaloneSchedulerBackend: Executor app-20210406093716-0015/8 removed: Command exited with code 1
2021. 4. 6. 오후 6:37:33 21/04/06 09:37:33 INFO BlockManagerMasterEndpoint: Trying to remove executor 8 from BlockManagerMaster.
2021. 4. 6. 오후 6:37:33 21/04/06 09:37:33 INFO BlockManagerMaster: Removal of executor 8 requested
이렇게 running했다가 바로 exited로 죽는 현상이 반복되었다. 찾아보니 github.com/bitnami/charts/issues/2883 요 글에서 내가 spark-submit을 하는 pod1 을 pod2에서 인식을 못하니 내 pod1의 주소를 --conf spark.driver.host=172.18.0.5 처럼 명시하라고 한다. spark submit docker가 돌고있는 node를 고정시키고 spark.driver.host옵션을 제대로 넘겨줬다. 이번엔 다른 에러가 발생한다.
21/04/06 09:45:14 WARN Utils: Service 'sparkDriver' could not bind on port 18000. Attempting port 18001.
21/04/06 09:45:14 WARN Utils: Service 'sparkDriver' could not bind on port 18001. Attempting port 18002.
21/04/06 09:45:14 WARN Utils: Service 'sparkDriver' could not bind on port 18002. Attempting port 18003.
spark.driver.host는 외부에서 보는 내 아이피주소이고,(또 그렇다고 공용 ip는 아님.) spark.driver.bindAddress는 내부에서 보는 사설 아이피 주소이다. 이거 두개를 설정해주고도 안되었는데 어떤 스택오버플로우 글에서 또 찾았다. github.com/tashoyan/docker-spark-submit 요게 spark-submit을 해주는 도커인데 도커파일을 살펴보면 아래 포트가 열려있음을 확인할 수 있다.
1. 18000, 18001, 18002는 위에 적었듯이 사용하는 3개 포트이므로 HostPort로 포워딩해줌. (예전에 qkqhxla1.tistory.com/1102 요글에서 내부 통신용으로는 clusterport로 오픈하는게 맞다고 했었는데 이 경우에서는 hostport로 열어주지 않으면 안 되었다.)
2. driver_host, spark_server_address환경변수 설정
3. driver_host를 고정해줬으니 spark-submit이 돌 pod도 driver_host의 node로 고정