www.edureka.co/blog/spark-architecture/#:~:text=Scala%20and%20Python.-,Spark%20Architecture%20Overview,Resilient%20Distributed%20Dataset%20(RDD)
에서 필요한 정보만 가져다가 정리합니다.
바로 앞 글처럼 스파크가 어떻게 동작하는지는 알아두고싶어서 정리합니다.
Spark Architecture Overview
아파치 스파크는 모든 컴포넌트와 레이어가 느슨하게 결합된, 구조적으로 잘 정의된 아키텍쳐이며, 다양한 라이브러리가 통합되어 있습니다. 스파크 아키텍쳐는 두가지 개념을 기반으로 만들어졌습니다.
Resilient Distributed Dataset(RDD)
Directed Acyclic Graph(DAG)
Resilient Distributed Dataset(RDD)
RDD는 어떤 스파크 어플리케이션이든 갖는 '집짓기 위한 블록'입니다. RDD는 각각 아래를 의미합니다.
Resilient : 실패했을때 데이터를 재복구 가능함.
Distributed : 클러스터의 다양한 노드로 데이터가 분산됨.
Dataset : 파티셔닝된 데이터들의 컬렉션.

위 그림은 분산된 컬렉션에 있는 추상화된 데이터들의 레이어입니다. 데이터들은 기본적으로 immutable이고, lazy transformations을 따릅니다. (lazy transformations : 실제로 필요할때까지 실행을 늦추는 것. 스파크 속도에 중요한 역할을 하며, driver가 실제로 일부 데이터를 요청할때만 실행하는것을 말합니다.)
이제 어떻게 동작하는지가 궁금할 겁니다. RDD에 있는 데이터는 키를 기반으로 덩어리로 나뉘어져 들어갑니다. RDD는 resilient하므로 일부 데이터에 문제가 생겼을 경우 여러개의 실행 노드에 복제되었던 데이터로부터 빠르게 복구가 가능합니다. 그러므로 한 실행 노드가 고장나면, 다른 노드가 작업을 대신 합니다. 이러한 특징들이 여러 노드의 자원을 사용하여 데이터에 함수적인 연산(functional calculations)을 빠르게 수행하도록 합니다.
한번 RDD를 만들면 immutable합니다. imutable하다는 것은 만들어진 이후 객체의 상태가 수정(modified)될수 없다는 의미입니다. 하지만 분명히 변환(transformed)될 수 있습니다.
분산 환경에 대해 보자면, RDD 내부의 데이터셋은 클러스터의 다른 여러 노드 안에서 계산될 수 있는 논리적인 파티션으로 나뉘어져 있습니다. 이러한 특징 덕분에 변환(transformations)과 액션(actions)을 완벽하게 병렬적으로 진행할수 있습니다. 또한 스파크가 모든 분산 처리 환경에 대해서 신경쓰므로 사용자는 분산 처리 환경에 대해 신경쓰지 않아도 됩니다.

RDD를 만드는 두가지 방법이 있습니다. 현재 드라이버 프로그램에 존재하는 컬렉션을 병렬화하거나, 공유 파일 시스템이나 HDFS, HBase같은 외부 저장소의 데이터셋을 참조하는 방법입니다.
RDD로 두가지의 명령을 수행할 수 있습니다.
1. Transformations(변환) : 새로운 RDD를 만드는 명령입니다.
2. Actions(액션) : RDD에 계산 등을 적용해 결과값을 돌려받는 명령입니다.
Working of Spark Architecture
위에서 기본적인 아키텍쳐에 대해서 보셨으니 이제는 어떻게 동작하는지를 집중해봅시다.
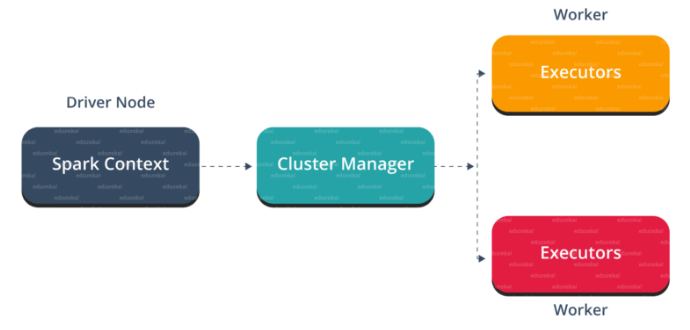
마스터 노드에는 프로그램을 돌리는 driver program가 있습니다. 내가 짠 코드는 driver program으로써 동작하고, 대화형 쉘을 사용한다면, 쉘이 driver program으로 동작합니다.

driver program 에서 가장 첫번째로 할 일은 Spark Context를 만드는 겁니다. Spark Context를 모든 스파크가 할수 있는 작업들로 가기 위한 게이트웨이라고 생각합시면 됩니다. DB연결과 비슷합니다. DB에 어떤 명령어를 실행하기 위해 입력하면 DB커넥션을 통해서 전달됩니다. 이와 비슷하게 스파크에 어떤 명령어를 실행하기 위해서는 Spark Context를 통해 전달됩니다.
Spark Context 는 cluster manager과 작업들을 조정하기 위해 협업합니다. driver program과 Spark Context는 클러스터 내부의 작업 실행을 책임집니다. 작업은 여러개의 테스크로 나뉘어서 워커 노드로 분배됩니다. Spark Context에서 생성된 RDD는 언제든지 여러개의 노드로 분배되거나 캐싱될수 있습니다.
worker node들은 테스크를 실행시키는 slave node입니다. 이 테스크들은 워커 노드 내부의 파티셔닝된 RDD위에서 실행되고, 실행 결과를 Spark Context로 돌려보냅니다.
워커 노드를 증가시키면 잡들을 더 여러개의 파티션으로 나눌 수 있고 더 여러개의 시스템에서 병렬적으로 실행이 가능하므로 당연히 실행 속도가 빨라집니다.
아래의 시각화 자료로 스탭별로 살펴봅시다.

step 1: spark code를 submit합니다. 코드가 submit되면 driver는 코드를 변환(transformations)과 액션(actions)을 명시적으로 정의해 DAG로 넣습니다. 이 단계에서 파이프라이닝 변환과 같은 최적화도 실행합니다.
step 2: 이후 DAG라는 논리적인 그래프를 물리적인 실행 계획 안에 스테이지를 나눠서 넣습니다. 물리적인 실행 계획으로 변경 후에, 각 스테이지에 테스크라고 불리는 물리 실행 계획 유닛을 만듭니다. 테스크들은 묶여서 클러스터로 보내집니다.
step 3: driver는 클러스터 매니저와 자원에 대해 이야기를 나눕니다. 클러스터 매니저는 driver를 대신해서 워커 노드에서 익스큐터를 실행합니다. 이 시점에 driver는 데이터의 위치에 기반해서 익스큐터에게 테스크를 보냅니다. 익스큐터가 실행되고나서 driver에 등록합니다. 그러면 driver에서 익스큐터가 어떤 테스크를 실행시키는지 모니터링이 가능합니다.
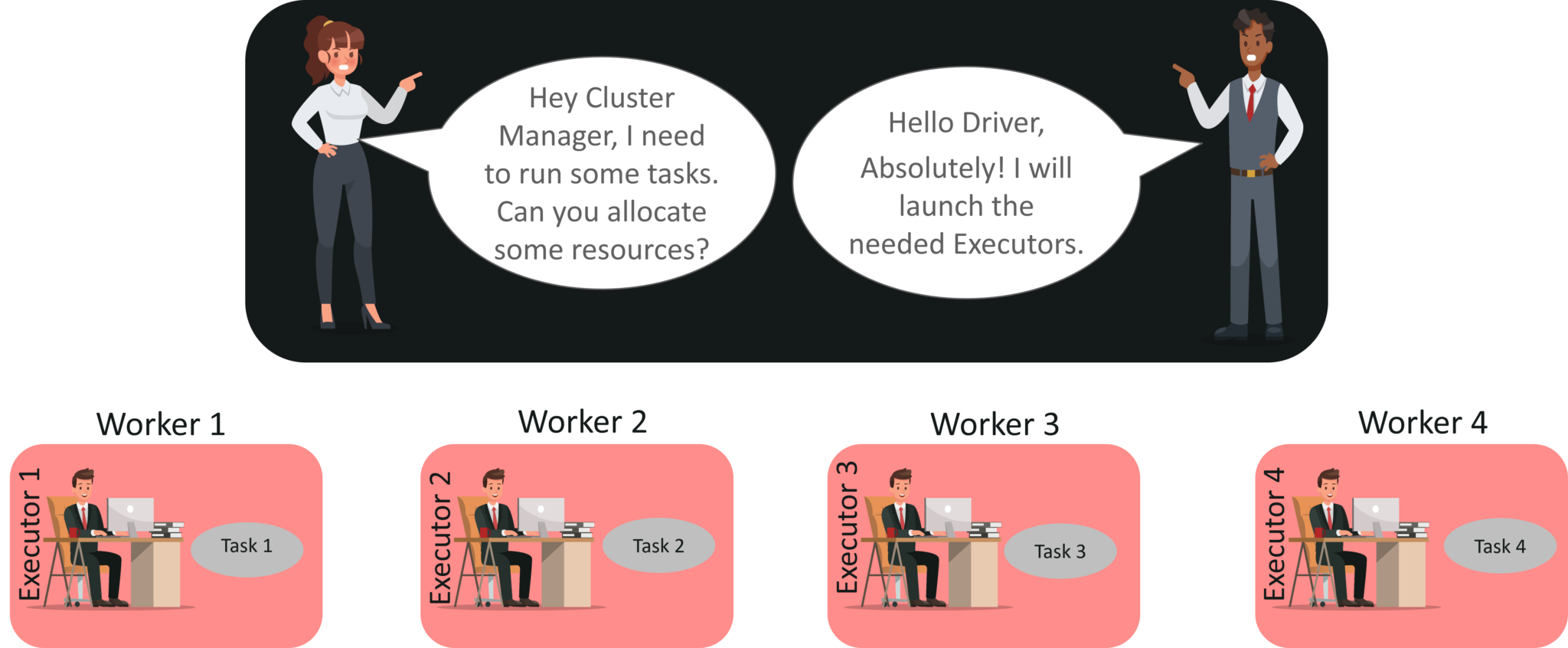
step 4: 테스크가 실행되는동안 driver는 익스큐터가 실행되는걸 모니터링합니다. driver는 데이터 위치에 기반해 미래의 테스크 할당 계획을 수립합니다.
'data engineering' 카테고리의 다른 글
| spark streaming(dstream, structured streaming) 정리 + 삽질 (0) | 2021.05.06 |
|---|---|
| kafka관련 좋은글 링크 (0) | 2021.05.03 |
| Hive Architecture, Job exectution flow (0) | 2021.04.11 |
| spark installation using helm, spark-submit docker (0) | 2021.04.06 |
| parquet vs orc vs avro (big data file format ) (0) | 2021.03.25 |