kibana에 대해서는 qkqhxla1.tistory.com/1024 에서 정리를 가볍게 했었는데... 저 글에서도 적었지만 겨우 한 글에 너무 전반적인 내용을 다 적으려고 하다가 이도 저도 아닌 글이 되버렸다.
이번에는 실제로 사용하는 데이터를 이용하여 가장 헷갈리는 부분인 키바나 gui를 이용해 시각화하는 부분만 다룰 예정이다.키바나 gui를 사용해서도 만들 수 있는 그래프가 상당히 많은데, 그중에 많이 사용하는, 간단한 패턴만 몇개 적는다. 다른 복잡한 작업들도 할수 있을건데 내 입장에서는 대충 아래 패턴정도로 키바나 파악이 끝나면 대충 이리저리 만져서 만들어낼 수 있다고 생각한다. '이렇게 넣으면 이렇게 그려지겠지' 감을 잡는게 가장 어려웠다.
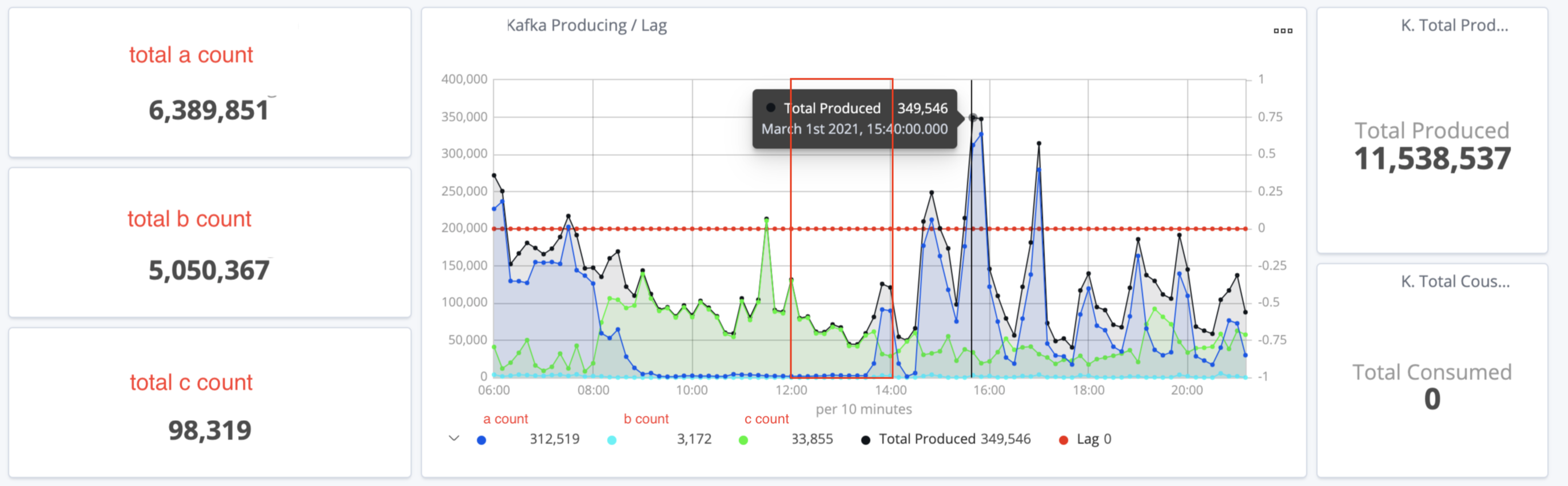
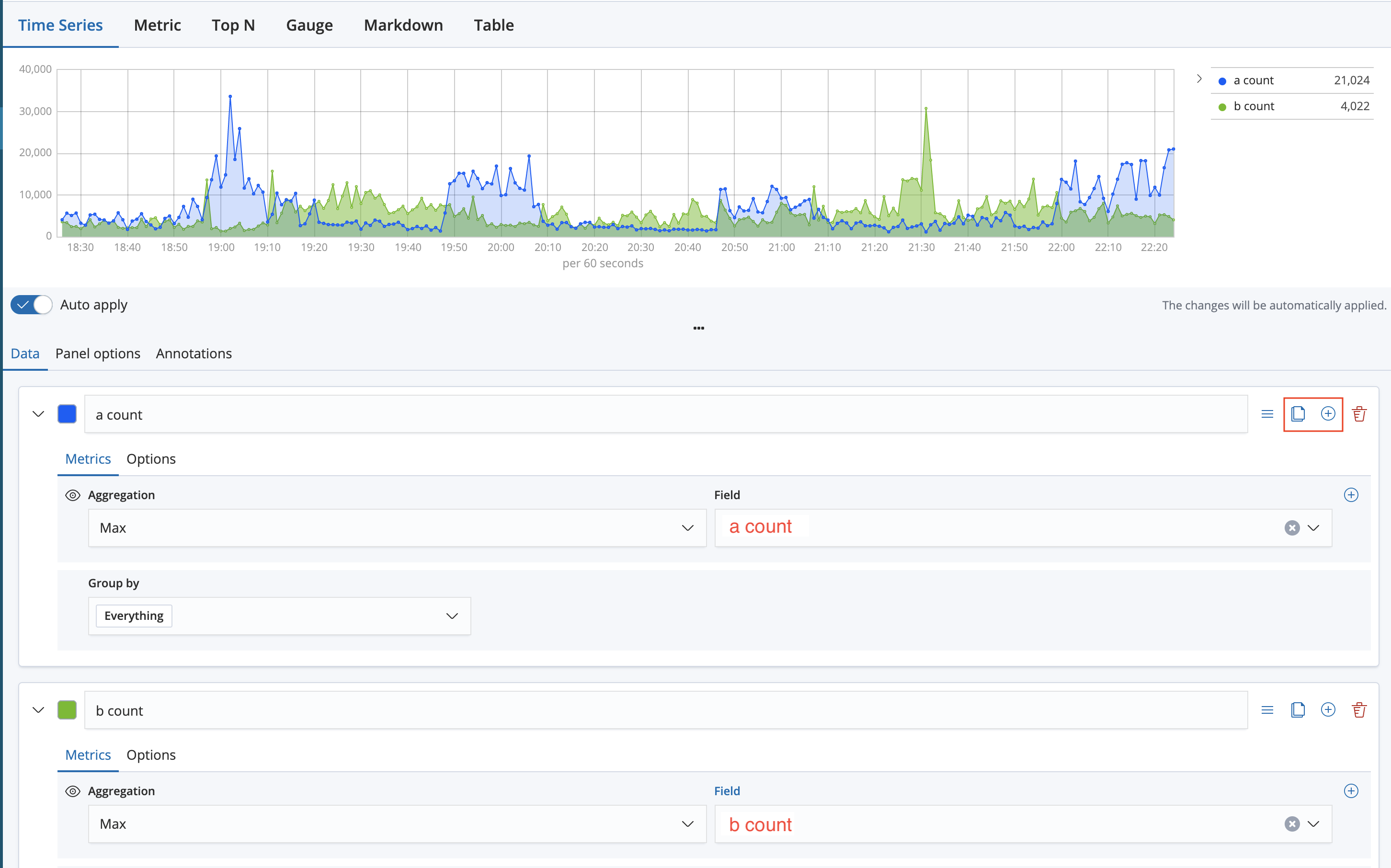
es로 매분 이 포맷의 데이터를 쏜다. a_count, b_count, c_count는 매분 내가 카프카로 프로듀싱하는 데이터의 카운트이다. 이 카운트들이 높아지거나, 낮아지거나, 또는 특정 시간에 몇개가 수집되는지를 모니터링하고 싶다. 대충 아래와 같은 캡쳐화면이 결과적으로 나오게 된다.
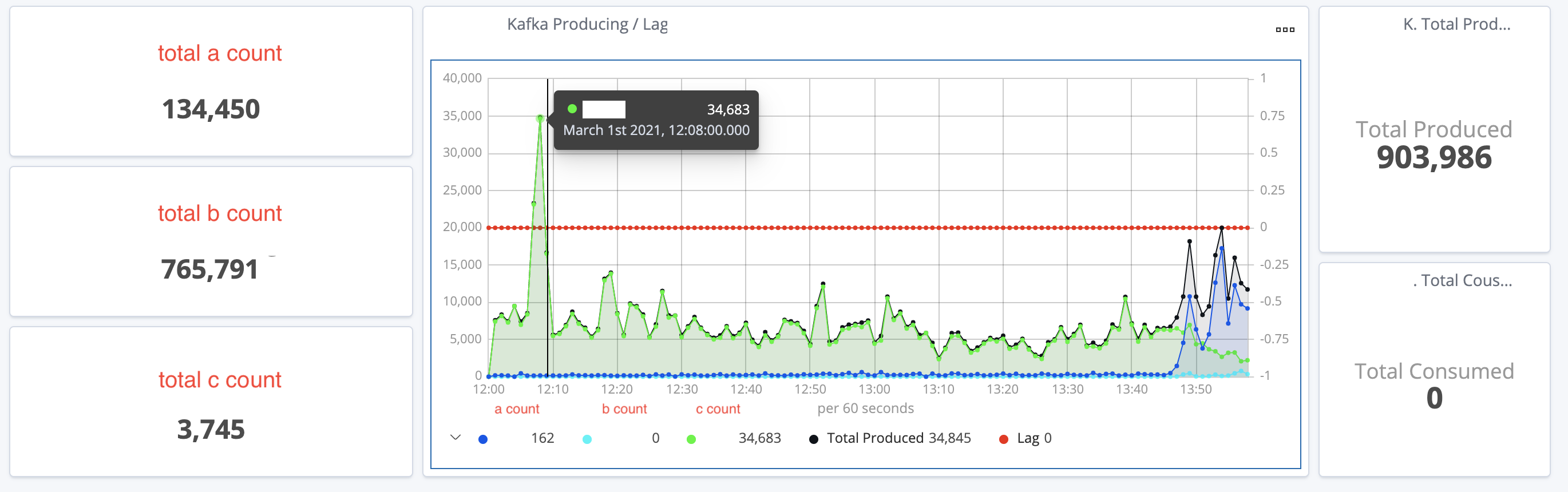
현재 위의 캡쳐는 6시~22시쯤으로 필터링을 해서 보여준건데, 자동으로 왼쪽에 필터링된 시간동안의 총 a, b, c 카운트가 보인다. 중간의 그래프는 적당히 시간을 보기좋게 나눠서 그 시간대쯤에 쏘아진 양을 뭉쳐서 보여주는데, 아래에 캡션으로 카운트가 나온다. 그래프 중간에 마우스가 올라간 곳의 total produced는 저 검은 시간대(15:40)쯤의 기록들을 모아서 보여준다. 15:40에 정확히 349,546개가 프로듀싱된게 아니라, 대충 저 근처 시간대의 카운트들을 취합한 값이 저거다. 시간 필터를 저해서 그렇지, 최근 15분 등 좁은 시간을 보게 되면 total produced값은 뭉쳐서 보여주는게 아니라 촘촘히 보여주기 때문에 작아질 것이다. 이해를 위해서 위 캡쳐에서 빨간색 상자로 표시된 시간인 12:00~14:00으로 필터건 결과를 가져왔다.
보기좋게 그래프가 변화한 것을 알 수 있다. 다시 만들걸 해석해보자면. total a count는 필터링된 시간(12:00~14:00)사이의 총 들어간 a count값이다. 오른쪽의 total produced는 total c count + total b count + total c count의 값이다. 그리고 현재 마우스가 있는 c count가 34,683인 시간대(12:10쯤)에는 b count가 한개도 들어오지 않았다. 이런식으로 만들어놓으면 특정 분이나 시간동안의 카운트를 눈으로 보기 쉽고, 언제 뭐가 튀었거나 안 돌았는지 확인하기가 편하다.
첫번째로 만들건 위의 대시보드에서 중간의 그래프다. Visualize탭에서 +를 눌러 새로 탭 하나를 만들고 Visual builder를 선택한다.
Panel options탭에서는 위처럼 설정해준다.
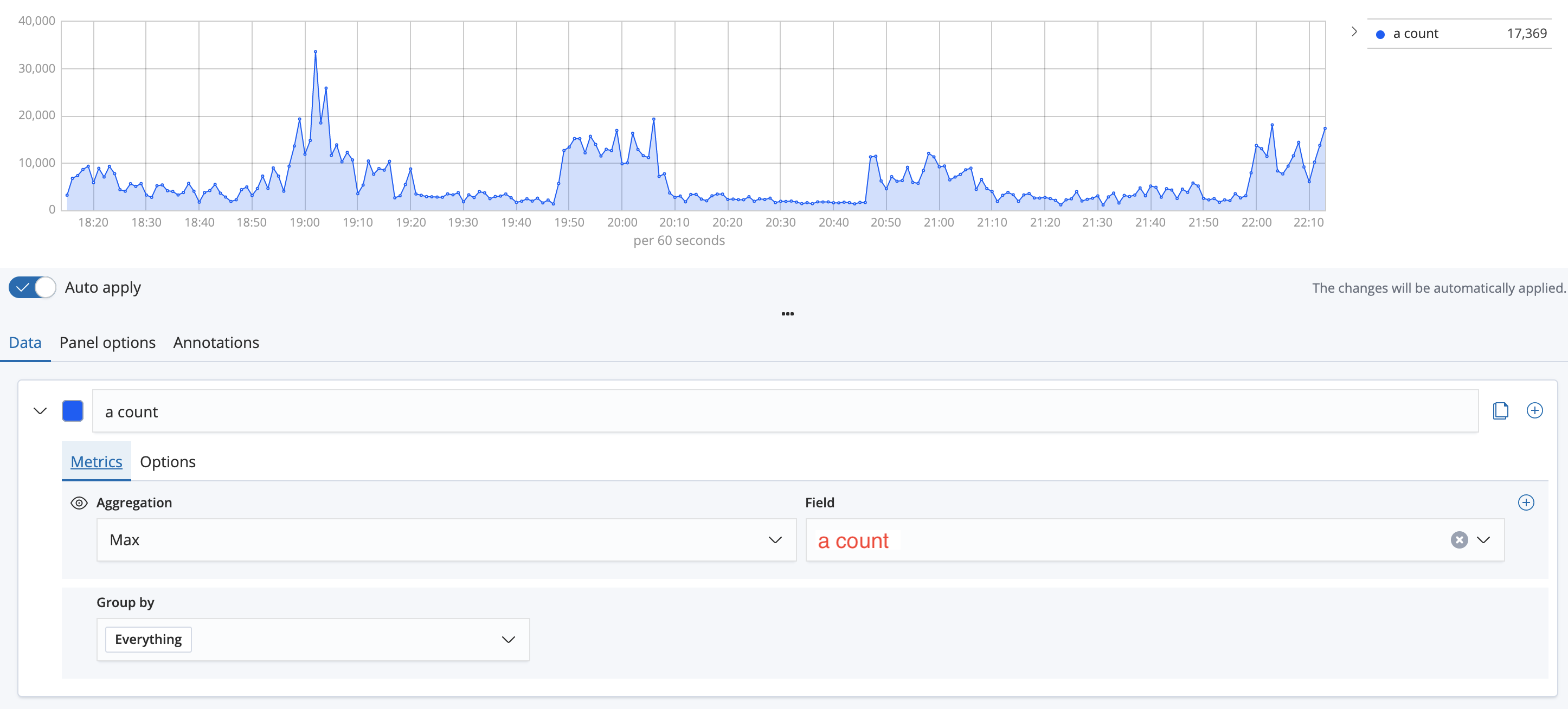
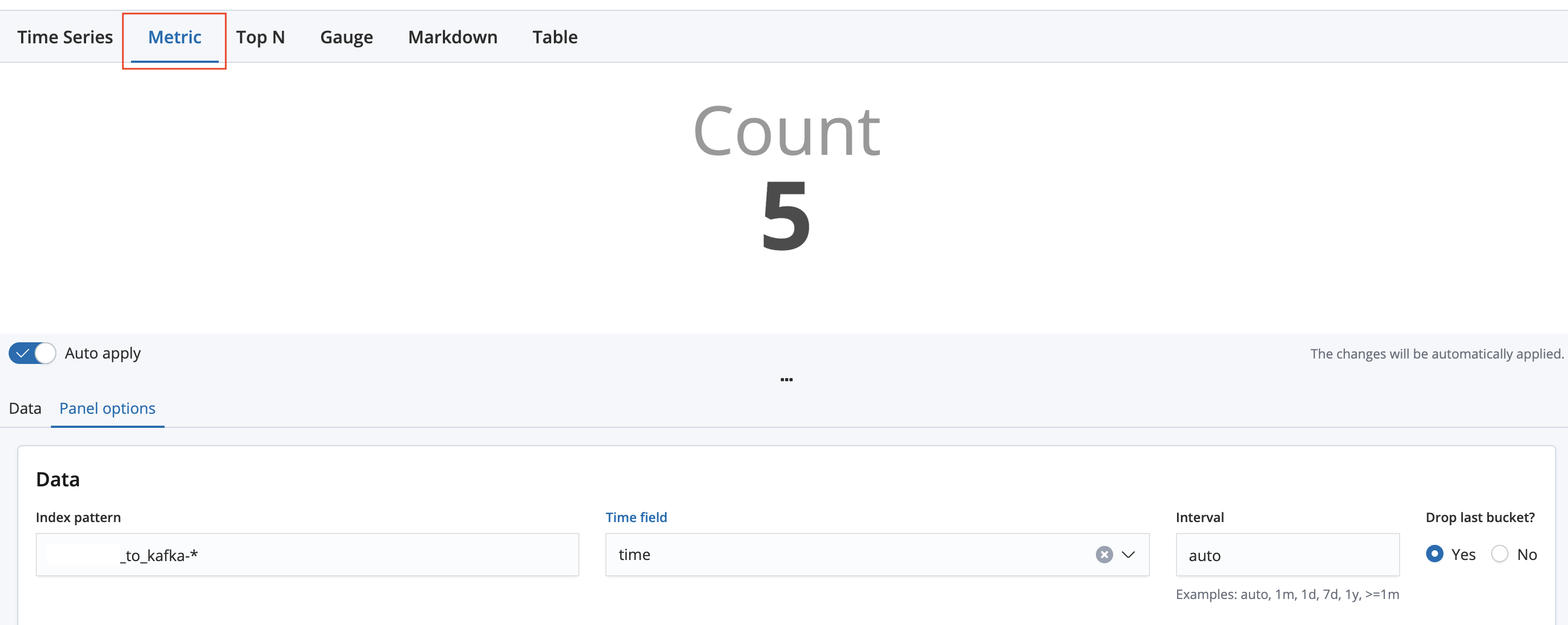
Index pattern에 위에서 보이는 인덱스인 test_to_kafka-2021.02를 가져오기 위해 test_to_kafka-*로 패턴을 잡는다. 인덱스 이름의 포스트픽스로 현재 년-월을 붙이는게 나중에 관리상 편하다. Time field에는 내가 현재 시간을 넣어준 필드인 time을 적는다. Interval은 나중에 다시 설명할건데 auto면 키바나가 알아서 적당한 범위로 잡아서 걸러준다는 말이다.
현재 나는 1분단위로 데이터를 쏘느라 1m처럼 해도 되지만 저거로 한 이유는 그래프가 너무 촘촘히 그려지기 때문이다. 밑 캡쳐화면을 보면 auto여서 점간의 간격이 보기에 좋은데, 1m으로 하면 실제 1분마다 점을 찍게 해서 더 정교하게 보일순 있어도 그리 보기좋지는 않다.
Data탭에서는 이처럼 넣어준다. 파란색 말고 원하는 색을 지정해도 좋으며, Data -> Metrics의 Aggregation에는 집계 함수인 Max, Min, Sum등등을 쓸 수 있는데 그래프를 그릴때는 어차피 한 도큐먼트에 하나의 값이 들어가 있어서 그런지 몰라도 Max, Min, Sum의 차이가 없다. 여기서 Aggregation의 Max함수는 위에서 말했듯이 키바나는 적당한 시간대로 뭉쳐서 그래프를 그려주는데, Max이면 적당한 시간대중의 Max값만 점을 찍어서 그리는게 아니라 내가 매분 쏜 데이터의 Max값들의 합을 보여준다. Sum이면? 내가 매분 쏜 데이터의 Sum값들의 합을 시간대로 뭉쳐서 보여준다. 근데 나는 한 도큐먼트에 하나의 a count만 넣어서 보내서 그런지 몰라도 Max, Min, Sum값이 다 동일하게 나온다.(값이 하나면 Max, Min, Sum이 동일한 값일것이므로인듯 싶음.) 근데 es로 데이터를 쏠때 파이썬 딕셔너리로 만들어서 보내느라 동일한 두개의 키가 들어갈 수가 없다.(???) 이건 아직 잘 모르겠는 부분인데 그러면 Max, Min, Sum은 키바나에서는 어떻게 써야 다르지.. 하는 고민이 있다. 만약 내가 어떤 값에 대해서 Max, Min 이 필요하면 es로 쏘기 전에 미리 데이터를 만들어서 Max_val이런식으로 만들어서 보낼 것 같다.
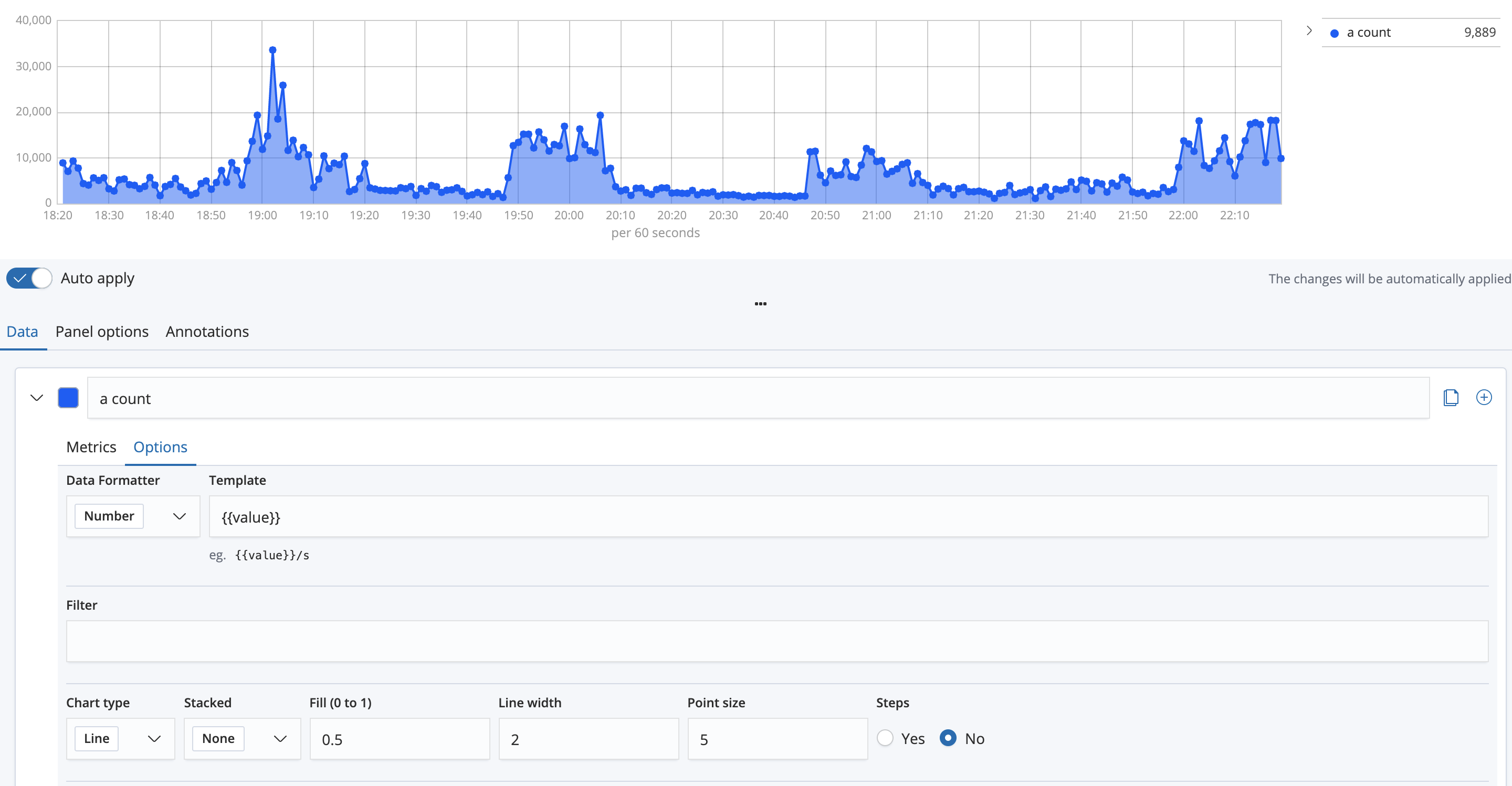
어쨌든 셋중 아무거나 하나를 선택해주고 난 파란색으로 a count의 값을 표시할 것임으로 a count를 선택해준다. 그리고 Data -> Options탭에서는 더 예쁘게 그리는 옵션을 추가할 수 있다.
예로 몇개만 보자면 Fill값은 내부를 파란색으로 얼만큼 채울건지,(현재는 0.5지만 위에는 0.2였음.) Line width는 선의 굵기, Point size는 그래프에서 점의 크기이다. 가장 눈에 확 들어오는 옵션이어서 바꿔봤고, 이거말고도 축이 두개면 축을 왼쪽 오른쪽으로 분리한다던지 등등을 바꿀수 있다. 바꿔가면서 가장 예쁜 옵션으로 커스터마이징하자.
그리고 빨간 네모로 표시된 clone series 를 눌러 하나를 더 만들고 동일하게 만들면 된다. 이런식으로 여러개를 만들어서 저장하면 끝난다. 키바나의 visualize에서 저장한 것들을 새 Dashboard를 만든 다음 Add로 탭 하나를 가져올 수 있다. 처음에는 위의 그래프만 있으므로 위의 그래프만 가져다가 붙여놓고 드래그로 적당히 탭의 크기를 조절해준다.
이번엔 필터링된 시간내에서 집계한 a count의 총 카운트 숫자만 보여주는 탭을 만들거다.
이번에도 Visualize탭에서 +를 눌러 새로 탭 하나를 만들고 Visual builder를 선택한다.
처음에 만들면 기본적으로 Time Series가 선택되는데, 이번에는 Metric탭을 선택한다.(왼쪽위 빨간색 상자) 그리고 Panel options에서 위에 그래프만들때와 동일하게 입력한다.
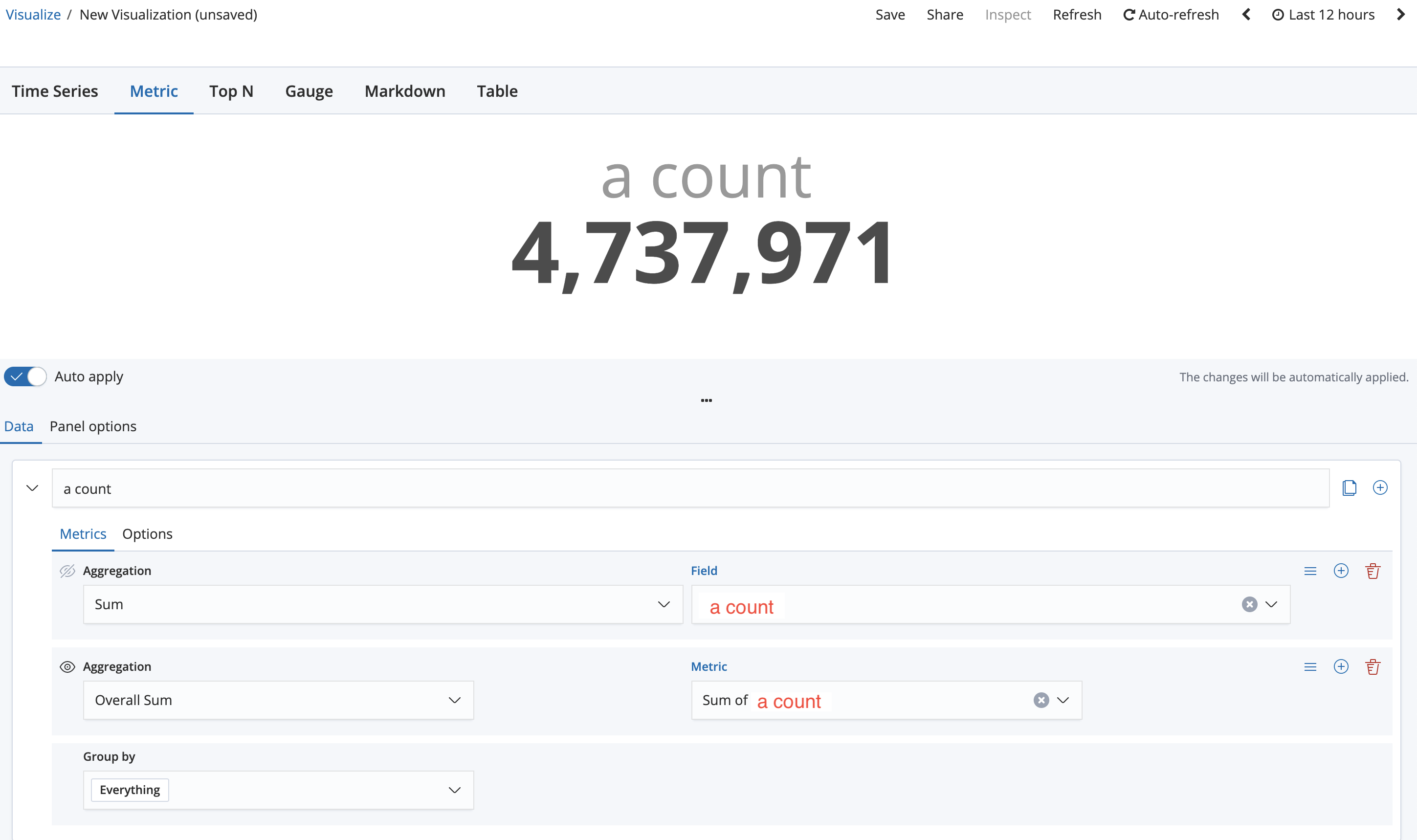
그리고 Data탭에서는 위처럼 입력한다. 기본적으로 Metric탭의 카운트는 현재 시간대의 카운트만 보여준다. 아래의 Data탭에서는 이번엔 Aggregation이 탭 하나에 두개인데, 이뜻은
첫번째 Aggregation에서는 a count의 Sum을 기준으로 그래프를 그릴거다.(그러니까 그래프로 따지면 각각의 점 하나임.) 두번째 Aggregation에서는 첫번째 Aggregation의 결과값들을 전부 Sum한 값을 보여줄거다.(Overall Sum)라는 의미이다.
결국 위에 보이는 숫자인 4,737,971은 '현재 필터링된 최근 12시간동안(위 캡쳐의 오른쪽 위에 시간) elasticsearch에 들어온 a count의 총합'이 나온다. 내 a count는 매분마다 카프카의 a토픽으로 프로듀싱된 갯수이므로 12시간동안 a토픽으로 프로듀싱된 총 갯수가 나온다.
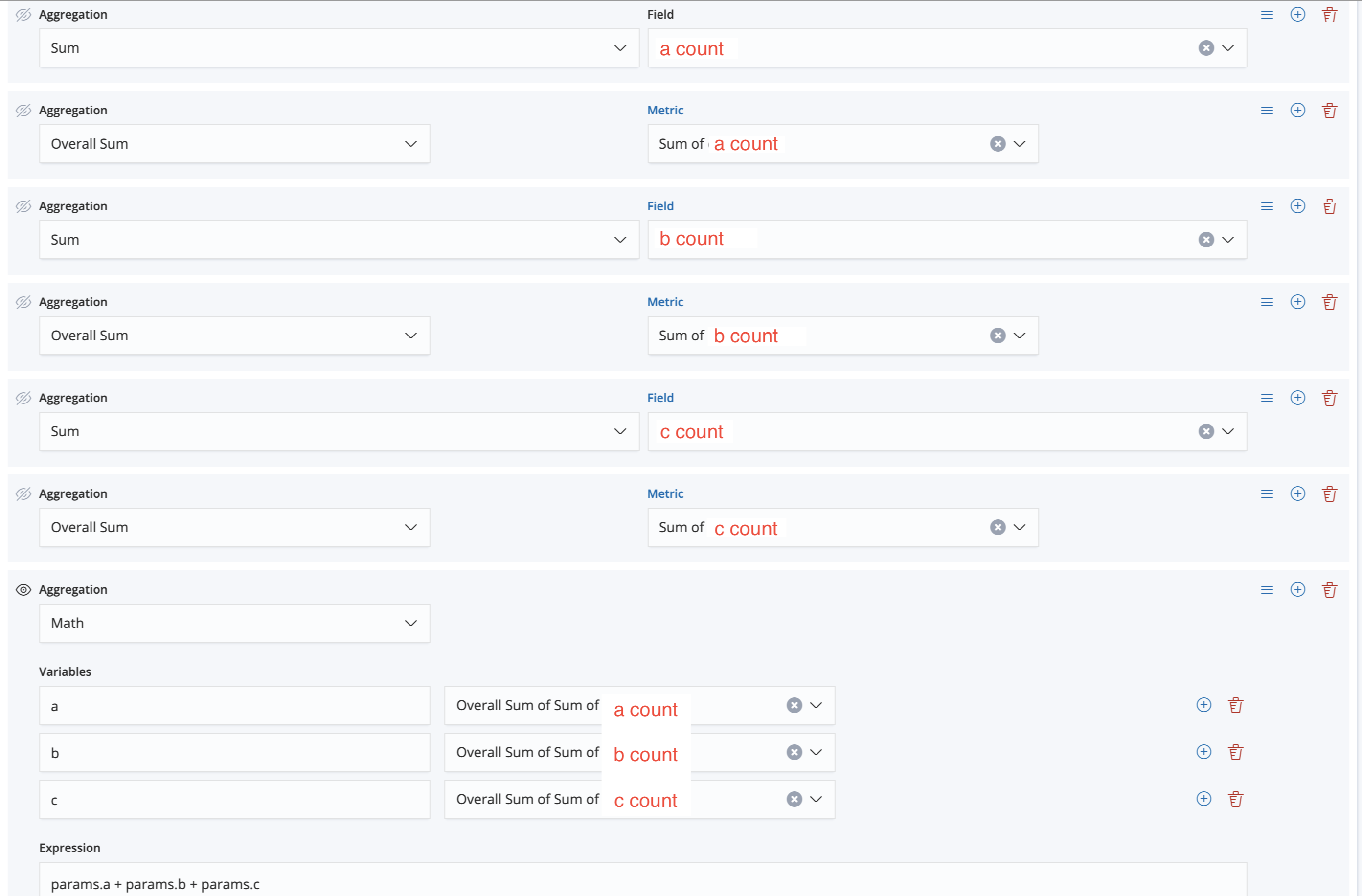
저것도 따로 저장하고 Dashboard에서 Add해서 드래그로 크기 조절을 잘 하면 맨 첫번째의 캡쳐화면이 나온다. 그런데 첫번째 캡쳐의 오른쪽 위의 총 프로듀싱된 카운트는 어떻게 한걸까? 아래처럼 복잡하게 하면 된다.
a count, b count, c count의 각각 합을 구하고 Math로 모든 집계를 받아서 합을 구해준다.
근데 이렇게까지되면 복잡해지니까 elasticsearch로 값을 넣기 전에 미리 프로그래밍으로 가공해서 넣어두는것도 좋은 방법이다. 사실 맨 처음에 넣은 es데이터를 다시 보면 알겠지만 데이터 내의 all_count가 모든 카운트를 더한 값이어서 그거 가져다가 써도 된다.
이번에는 모듈마다 데이터를 쏘는데 request.data_size에 쏜 데이터의 크기를 기록해놓는다. 모듈은 여러개가 있으며, 실시간으로 데이터를 쏜다.(fluentd로 쏨을 알 수 있다.) 모듈들 중 어떤 모듈이 데이터 사이즈가 큰지, 비율은 어떤지 파이 그래프로 보고자 한다.
첫번째로 visualize에서 pie로 그래프를 만든다. 그리고 위의 데이터에 대해서 인덱스는 현재 test2-*로 잡혀있는데 인덱스를 pie그래프를 선택할때 미리 선택해줘야 한다. 기본적으로 도넛 형태의 그래프가 만들어진다. 아래는 Options탭이다.
체크상자에서 도넛을 체크해제하면 파이 형태로 보이고, legend는 범례를 뜻한다. 그냥 그대로 놔두고 난 Show Labels를 클릭해서 부가적으로 더 잘 보이게 해줄거다. 이후 Data탭이 핵심이다.
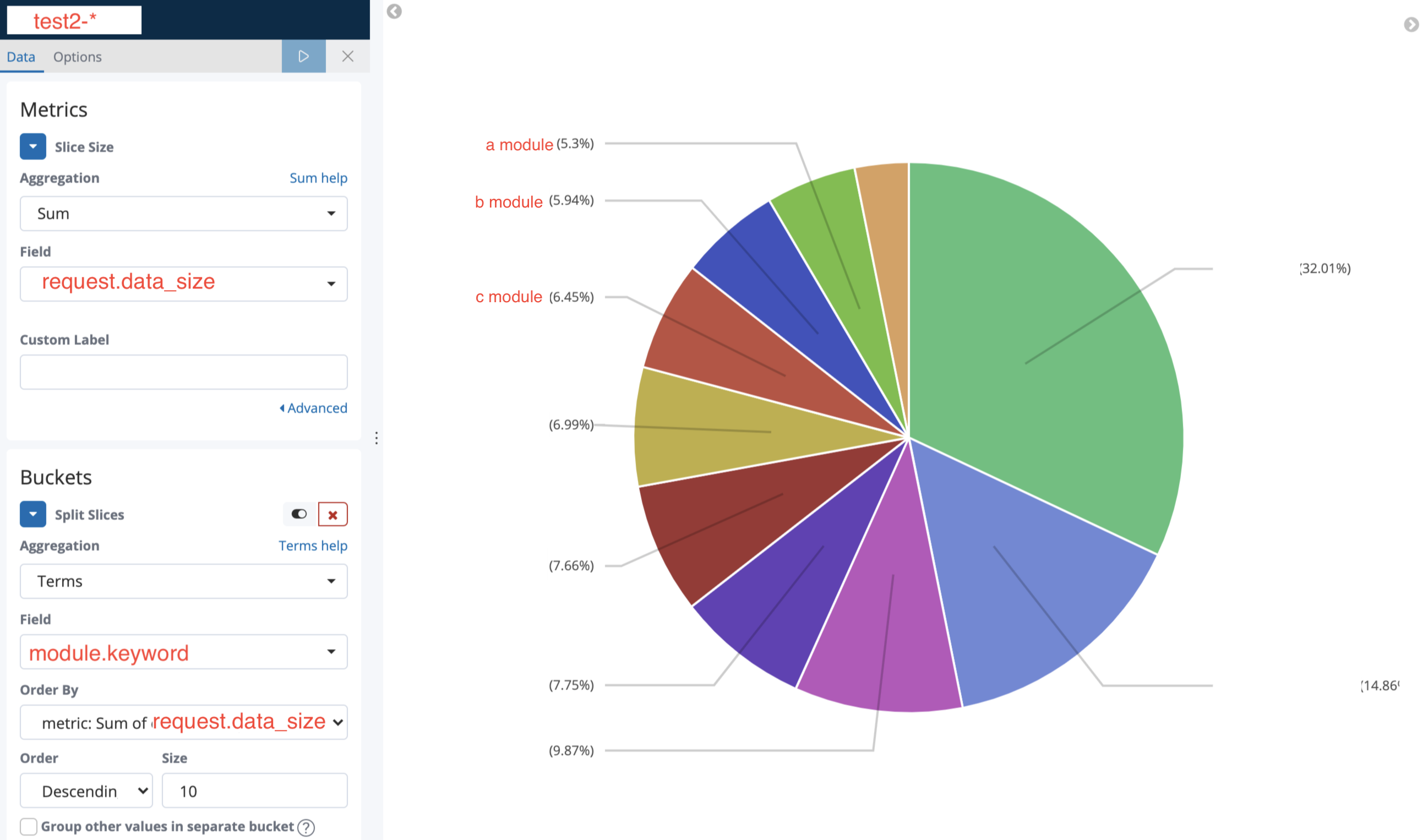
보면 Metrics와 Buckets가 있는데, Buckets은 어떤 필드를 기준으로 파이를 나눌거냐는 거고, Metrics는 분류된 파이값에 해당하는 값을 의미한다. 위에서 내가 만들고자 하는건 module별로 분류해서 request.data_size를 파이값으로 보여주고 싶다고 하였으니, Buckets에는 module을, Metrics에는 data_size를 넣어준다.
적었듯이 Metrics에는 request.data_size를 넣었고, Buckets에는 module을 기준으로 나누니 오른쪽에 예쁘게 그려지는걸 볼 수 있다. 비율도 보이고, 마우스를 올리면 필터링된 시간 내의 data_size의 총 합까지 출력된다. Buckets의 Order -> Descending으로 큰 값부터 내림차순을 선택했고, size에 10을 넣음으로써 상위 10개만 출력한다. 숫자는 늘리거나 줄일 수 있으며 맨 아래 보이는 Group other values in separate bucket를 체크해놓으면 나머지 값들이 other이라는 하나의 파이로 더 생성된다.
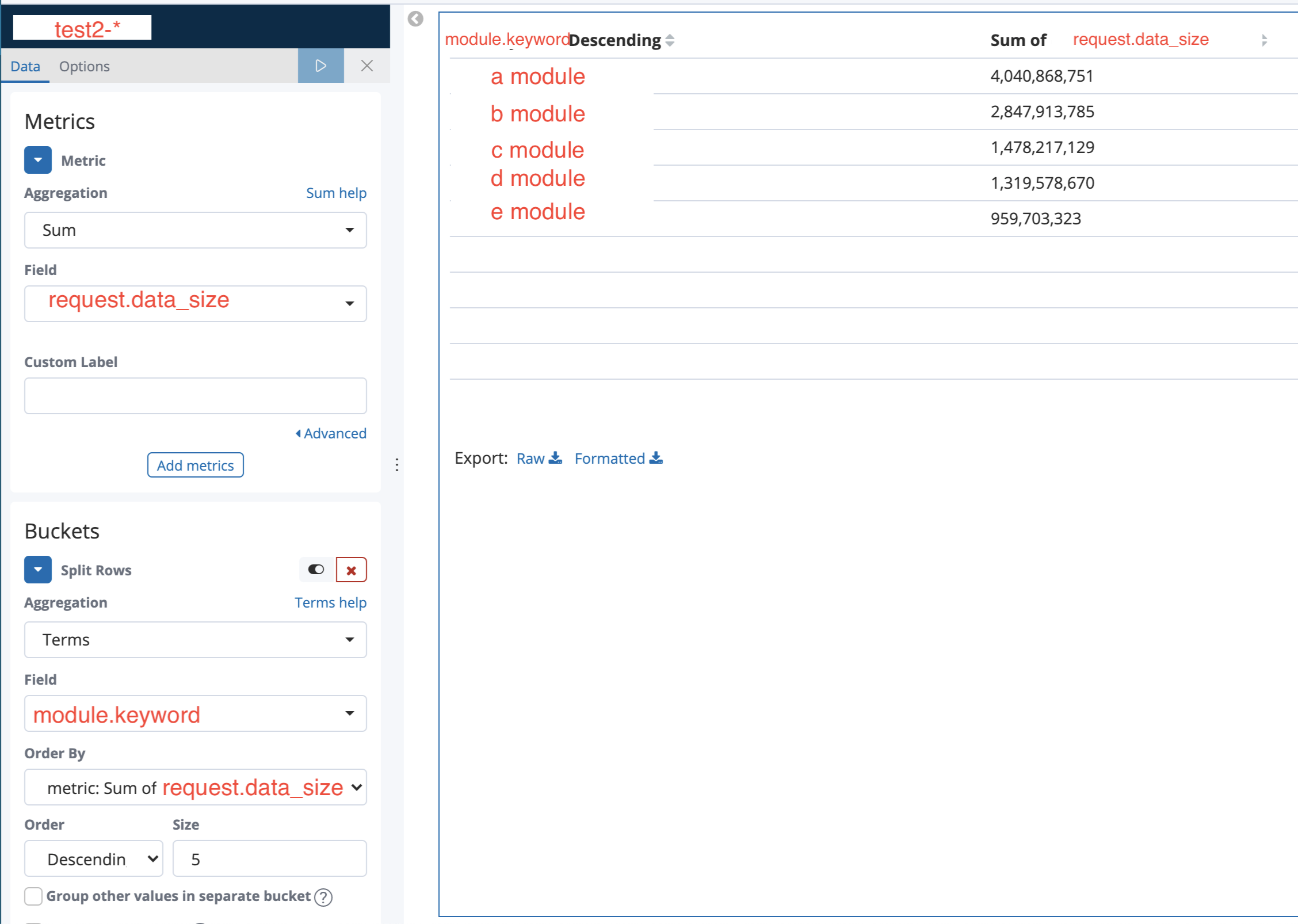
이해가 됐으면 막대그래프는 왼쪽의 메뉴가 동일해서 동일하게 입력하면 막대그래프가 보일거다. 파이나 막대처럼 시각화보다는 숫자가 중요한 경우 Data table로 만들어보자.