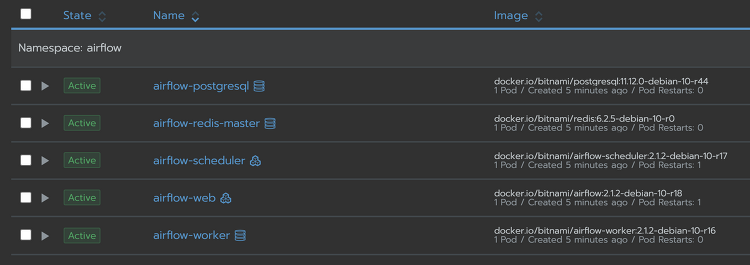
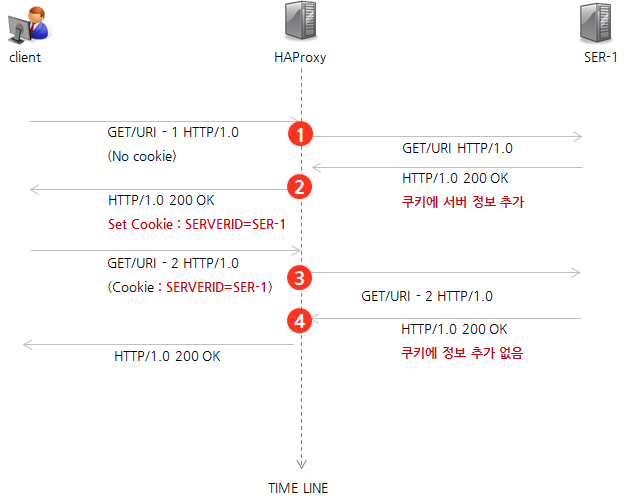
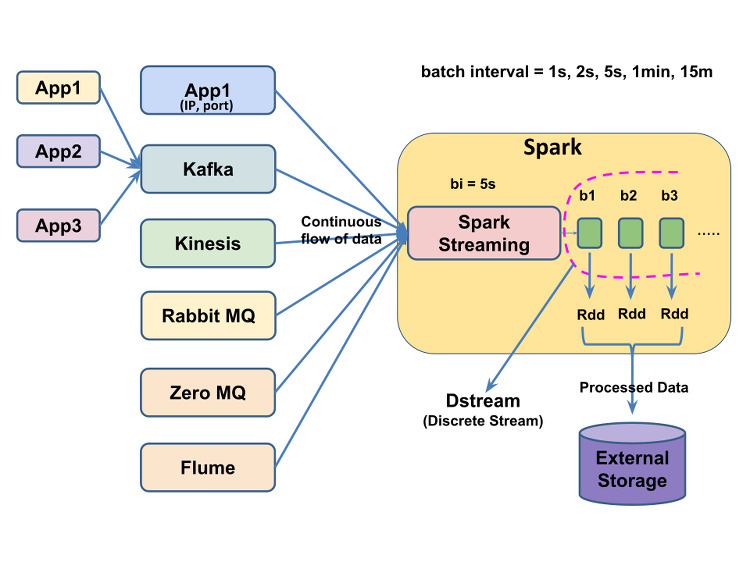
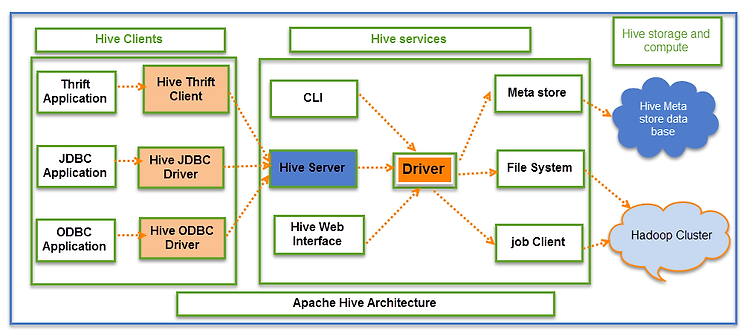
이전에 다른 제목으로 비슷한 글을 쓴적이 있는데 지금 보니까 정말 별다른 영양가가 없는 글이었다. 그래서 이전 글은 지워버리고 이번에 새로 얻은 지식까지 합쳐서 다시 정리한다. 이전에도 적은것같지만 bitnami라는 회사가 있는데 오픈소스로 helm chart를 상당히 많이 만들었고, 상당히 자주 업데이트해주면서 종류도 많고 완성도도 높아서 여기서 주로 가져다가 app을 만들어서 쓴다. k8s와 helm자체에 익숙하지 않았기에 여태까지는 기본으로 제공해주는 기능만 썼는데 더 필요한 기능이 있어도 수정할줄을 모르고.. 이러다보니 반쪽짜리 지식이 되버렸다. 빡쳐서 주말동안 커스터마이징을 하기 위해 공부와 삽질하고, 얻은 지식을 정리한다. 우선 목적을 적자면 airflow helm chart를 설치해서, ai..