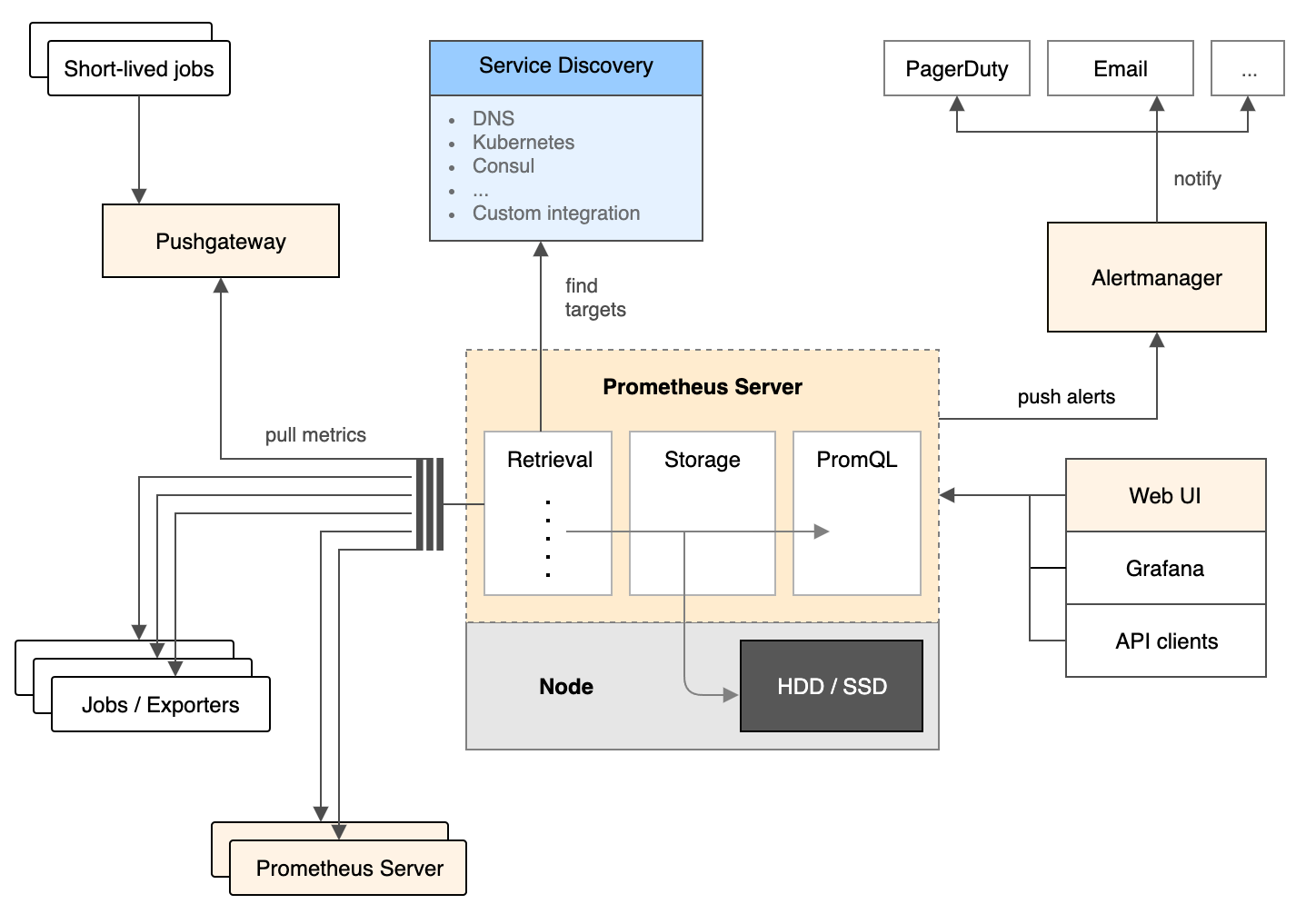
https://prometheus.io/docs/introduction/overview/ prometheus는 크게 Exporter, Push gateway, Server, Alert manager로 나눌수 있다. - Exporter는 모니터링 대상의 메트릭 데이터를 수집한다. - Push gateway는 Exporter처럼 메트릭을 수집하는데, 짧은 job의 메트릭을 수집한다. - Server는 Exporter가 수집해놓은 데이터를 Exporter가 열어놓은 HTTP 엔드포인트로 접근하여 메트릭을 수집한다. - Alert manager는 알람을 받을 규칙을 만들어서 규칙에 따라 알람을 보낸다.
희안한게 보통 Exporter역할을 하는, 메트릭을 수집하는 애들이 데이터까지 server에 보내주면 server에서 취합하는데, prometheus는 server에서 Exporter로 접근해서 가져오는 방식을 취한다. Exporter중에서는, k8s node resource들을 모니터링하기위해 Node exporter를 사용한다.
k8s에서 k8s node monitoring을 할것이므로 prometheus helm chart를 검색해보았다. prometheus official chart가 존재하였으며, 이 차트에서 값만 설정해서 설치하였다. prometheus의 node exporter로 k8s node의 모니터링을 하는게 상당히 흔한지 official chart에 기본적으로 node exporter관련 옵션이 들어가 있어서 별다른 설정을 해주지 않아도 prometheus만 설치하면 자동으로 모니터링이 되었다.
기본적으로 official chart를 설치하면 prometheus server, node exporter, push gateway, kube-state-metrics, alert manager를 설치해주는데, kube-state-metrics는 node exporter와 비슷하게 시스템 메트릭을 모아주는 서비스다. kube-state-metrics에 대해서 : https://medium.com/finda-tech/kube-state-metrics%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-1303b10fb8f8 결국 prometheus server가 중앙에 있고, kube-state-metrics, node exporter에서 로그를 수집해서 서버에서 가져가는 형태이다.
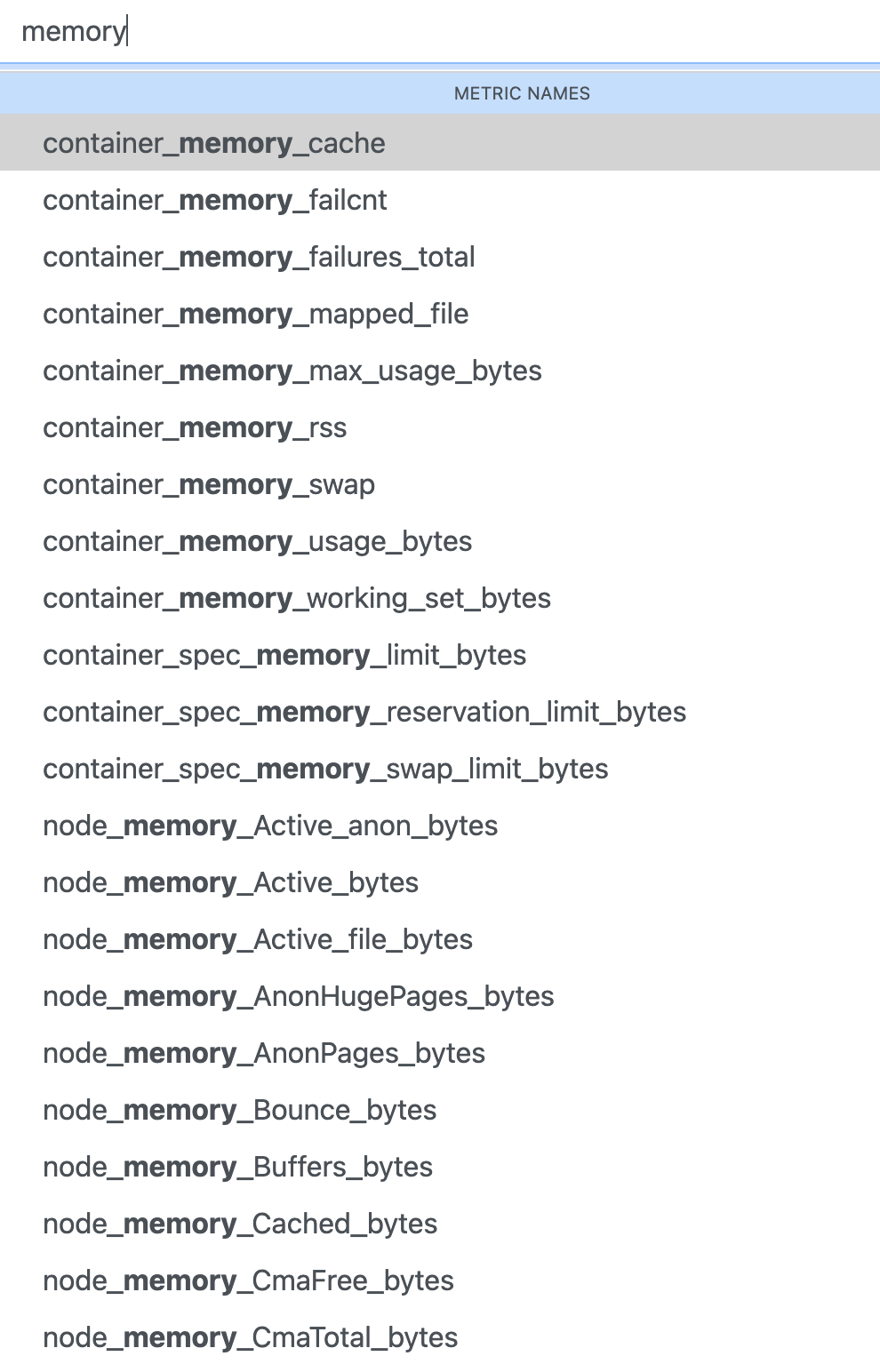
그리고 prometheus server gui의 graph탭으로 들어가면 수집되고있는 데이터들을 시각화해서 볼수있다. 메모리 사용 현황을 보기 위해 node_memory_Active_bytes를 입력하고 execute를 눌러보면 아래와 같이 메모리 사용량 모니터링이 되고있음을 확인할 수 있었다.
위의 node_memort_Active_bytes를 입력한 부분은 PromQL(prometheus query)이라고 하는 쿼리를 넣는 곳인데, 조건을 지정해서 필터링을 할 수 있다. 예로 조건을 하나만 걸어보면 조건에 걸린 결과값만 나옴을 확인할수 있다. PromQL의 경우는 이후 grafana에서도 동일하게 가져다 쓸수 있다.
helm에서 prometheus를 설치시 자동으로 k8s에 존재하는 모든 노드에 node exporter가 설치가 되는데, 어떻게 내 모든 노드정보를 알고 설치가 될까? 의문이었는데 DaemonSet이라는거로 설치를 한다. 읽어보면 DaemonSet은 모든 노드에 설치가 되며, node monitoring이나 log collection목적으로 사용된다고 한다.
그런데 prometheus에서 시각화를 테스트해본다고 가정하자. 리스트가 너무 많다. 예로 메모리를 모니터링한다고 가정하면 복잡하다. memory로 검색해보면 엄청 다양한 리스트가 나오는데 이름도 비슷비슷하고 뭘 써야할지 모르겠다. 내가 위에서 언급한 node_memort_Active_bytes말고도 container_memory_usage_bytes도 이름만 보면 비슷한 기능을 하는거로 보이는데 뭘 써야 할지 모르겠다. 삽질을 좀 했다.
container_memory_usage_bytes{beta_kubernetes_io_arch="amd64",
beta_kubernetes_io_instance_type="aws instance 사이즈",
beta_kubernetes_io_os="linux", container="POD",
failure_domain_beta_kubernetes_io_region="aws 존 정보.",
failure_domain_beta_kubernetes_io_zone="aws 존 정보.",
id="/kubepods/besteffort/pod00f7eb1c-1a0f-41ef-9221-7f1c71f2967d/4999ba28027dbde8ca96c6ea0cf1c7fbfbb8e4dc6598cd9521cfe000065e6818",
image="도커 허브 주소",
instance="aws 아이피 주소",
job="kubernetes-nodes-cadvisor",
kubernetes_io_arch="amd64", kubernetes_io_hostname="aws 아이피 주소",
kubernetes_io_os="linux",
name="pod 이름",
namespace="네임스페이스", node_kubernetes_io_instance_type="aws instance 사이즈",
node_role_kubernetes_io_worker="true",
pod="pod 이름",
topology_kubernetes_io_region="aws 존 정보.",
topology_kubernetes_io_zone="aws 존 정보."}
살펴보다 발견한게 job="kubernetes-nodes-cadvisor"이다. 위의 prometheus server gui의 status탭의 Targets의 화면을 캡쳐한게 있는데, 거기에 kubernetes-nodes-cadvisor이 있다. 이건 cadvisor 로그 수집기에서 가져온 로그라는 뜻인것 같다. cadvisor에 관해 찾아보니 공식 홈페이지가 나왔다. https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md 여기서 container_memory_usage_bytes를 검색해보면 아래와 같이 나온다.
grafana는 시각화를 전문으로 해주는 도구이며, 순수 grafana자체의 아키텍쳐 그림은 찾지 못했다. helm으로 설치해봐도 grafana 서버만 설치되는거로 보아 아키텍쳐랄게 딱히 없는것같다. grafana doc페이지를 들어가보면 여러개가 나오는데, 그라파나 집합체(??) 의 각각마다 아키텍쳐 그림이 따로 있는거로 보면 같은 집단의 다른 시스템이라고 봐도 될것같다.
grafana도 helm official chart가 존재했지만, bitnami grafana가 존재해서 이걸 설치했다. bitnami가 업데이트도 자주해주지만, 문서화가 상당히 잘되어있기 때문이다. 처음 설치하고 들어오면 자주 본 대시보드가 나타난다. 처음 할일은 위에서 세팅한 prometheus를 grafana의 data source로 등록하는거다.
데이터소스등록은 따로 어려울것없이 URL만 내가 설정한 url로 입력하고 테스트해보면 된다. test시 잘 되었다는 메시지가 나오면 dashboard를 만들어보자. 나같은경우 Panel을 추가해준 뒤, Metrics browser에 위에서 입력했던 PromQL인 node_memory_Active_bytes를 입력했다.
요런식으로 prometheus에서 잘 가져와서 그리고 있음을 확인할수 있다. 그런데 기본적인것만 사용한다고해도 추가하고 바꿔야할게 좀 많이 보인다. 첫번째로 메모리가 10Gi이렇게 읽기 쉽게 표시되는게 아니라 1000000000 이런식으로 그냥 숫자로 보이는것과, legend에 아이피 주소만 있으면 되는데 너무 많은 정보가 보이는것과, 메모리 사용량이 일정을 넘을시 알람을 추가하는거다. 먼저 단위부터 바꿔보자면 현재 그래프 형태가 오른쪽 위를 보면 Time series로 보이는데, Graph (old)로 변경했다. 그리고 Y축의 Unit를 bytes(SI)로 설정하고 Max값을 설정해주니 잘 변경되었다. legend표시문제는 {{instance}}로 필터를 걸어주었다.