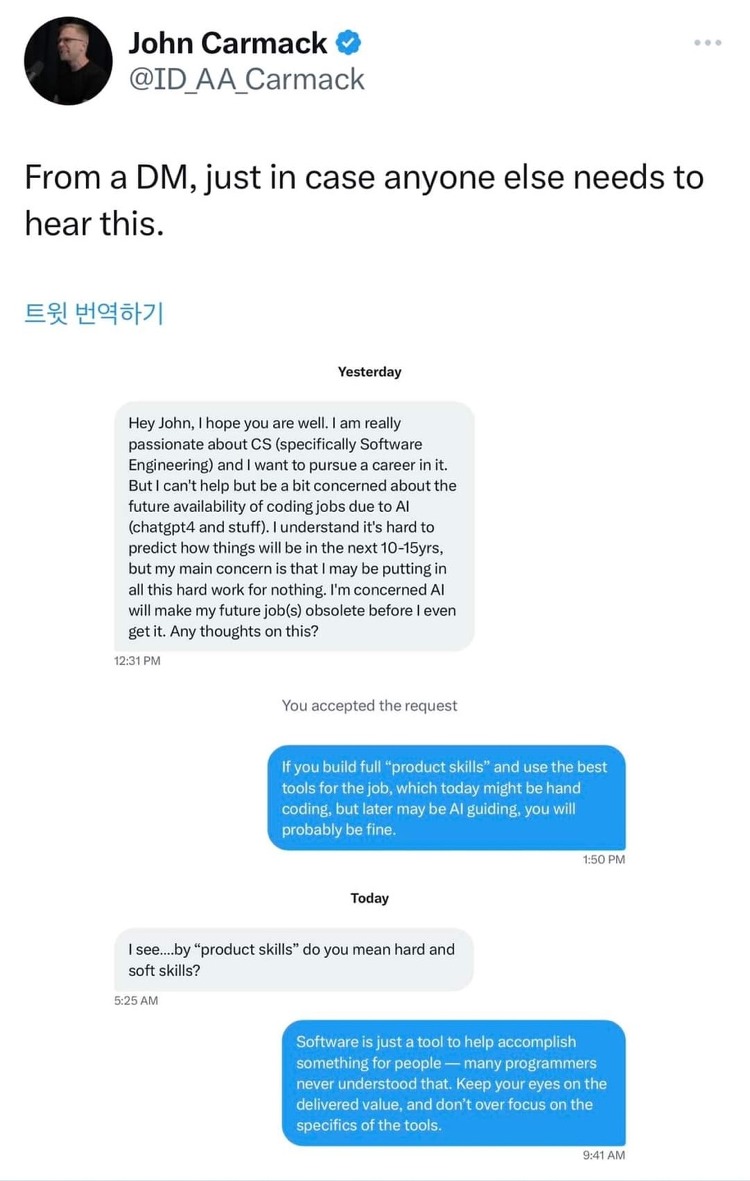
경기가 안좋아지면서, chatgpt라는게 나오면서 업계 분위기가 확확 변하는것 같다. 2년 전 코로나때만해도 개발자의 인기가 끝도 모르고 올라갔는데, chatgpt가 나오면서 개발자들 일자리 줄어드는거 아니냐, 경기가 안좋아지면서 들리는 다른 회사들의 연봉 상승률도 낮고, 이제는 누군가에게 개발자 하라고 추천하기도 그렇다. 작년까지만 해도 나름 기술적으로 알아낸거.. 그런 글을 종종 쓰다가 요즘은 일기형식의 이런 글만 쓰는데 바빠서인것도 있지만 근본적으로 마인드가 바뀐것 같다. 이전 직장에서 이전 팀에서의 역할과 지금 회사에서 지금 역할이 좀 달라져서 그런것 같은데.. 이전 팀에서 한 일을 요약하자면 '시키는대로 여러 일을 하는 개발만 하는 잡부'였다. 다른 팀과의 일정조율, 의사결정 등을 팀장님이 거의..