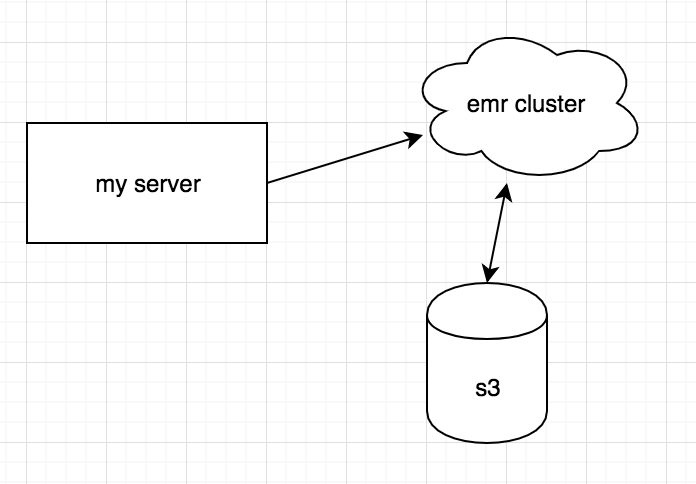
회사 내에 Amazon emr cluster서버가 있고, 현재 데이터 백업용으로 s3를 쓴다. ec2의 이슈 때문에 데이터가 날라가서 데이터를 s3에서 가져와서 다시 내 몽고디비 서버에 넣어야 했다. 새로 삽질한 경험을 적어놨다. 처음엔 단순히 내 서버에 spark를 설치 후 s3에서 데이터를 가져와 돌리려고 했다. 서버에 스파크를 설치하고, s3 parquet데이터를 가져오는 방법을 찾아보았더니 아래처럼 되었다. parquet은 파일 저장 포맷중 하나라고 한다. (https://spark.apache.org/docs/latest/sql-data-sources-parquet.html) from pyspark.sql import SparkSession spark = SparkSession.builder \..