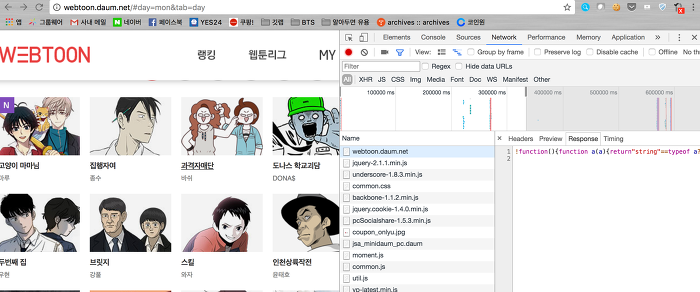
어떤 사이트에서 크롤링을 할 경우에 다음과 같은 단계를 거친다.1. 해당 페이지를 구성하는 데이터들을 어디서 받을수 있는지 찾는다.2. 해당 페이지에 요청을 보내는 코드를 짠다.3. 페이지 정보 등을 가져온 후 (파이썬의 경우) beautifulsoup나 정규식을 이용하여 필요한 부분을 크롤링하여 자동화한다. 일정 횟수 이상 크롤링을 해본 사람들이 보기에 가장 어려운 부분은 1번 파트이다.(처음 시작하는 사람은 구현부인 2,3번이 가장 어렵다)2번이야 항상 똑같으니 됐고, 3번이야 프로그래밍 지식이나 센스만 있으면 간단하다. 하지만 1번은 우리가 데이터를 찾아야 하기에 힘들다. 그리고 api처럼 공식문서도 당연히 없다. 아래에 다양한 사례와 1번의 데이터를 조금 더 쉽게 찾을 수 있는, 또는 크롤링하는 ..